
Over the last few months, the Borderlands Science team has made some significant progress crunching the data collected from the puzzles solved by the players. The goal here is to convert puzzle solutions from the players, which are slight modifications of an initial computer-generated sequence alignment of bacterial genetic sequences, into information we can use to improve this alignment.
We extracted the solutions that were close enough to an optimal tradeoff of minimum number of yellow tokens vs highest score, by comparing the solutions to one another.
Then, we went through all of these solutions and we sliced them into “votes” for every single position of the initial alignment. In other words, for each nucleotide (aka a letter in the genetic code, or a title in one puzzle), we look at the contribution of every single player that submitted a valid solution for a puzzle in which this tile was included. And then, the players vote on which nucleotide should be found in this position.
There is still a lot of work to do since we have to assemble these individual votes into a full DNA sequence that makes sense. The goal is to obtain a consensus sequence, or a sequence that has been “democratically elected” by players as the most valid solution.
We have processed so far a total of 166 million individual votes of this type. To give you an idea of how this looks like, we sorted the ~10,000 individual sequences we had in the initial alignment we worked with, and plotted the number of votes they received (aka the number of individual puzzle solutions they were featured in.
Note that it’s normal for all sequences to not be represented equally, as we aim for every puzzle to be different. This means that if two sequences are very similar over one region of the alignment, only one will be featured in puzzles, and we will use the results of that one to re-align the other one.

We will delve deeper into this in the future, but we have different categories of puzzles. Each category encodes a different “way” of converting a region of the original alignment into a puzzle. First, there is the “orientation” of the puzzle. In other words, the puzzles from the red category in the following plot are “upside down” in the game. In other words, some puzzles are taken from right to left (r ->l ) in the initial data, and some are taken from left to right (l -> r), and they are then rotated in the game to produce a gravity effect which the player is asked to offset using these yellow tokens The other difference is what we refer to as offset, which is a measure of how much “work” we expect the player to do to realign the sequences. A puzzle with offset=2 will see the player being offered more yellow tokens because the initial position will be further from a perfect alignment to the guides than in an average puzzle with offset=0.
In the following plot, the x axis is the column of the initial alignment (the initial sequences have a length of ~175 in that alignment), and the y axis is the number of annotations in millions, for each position for each category.
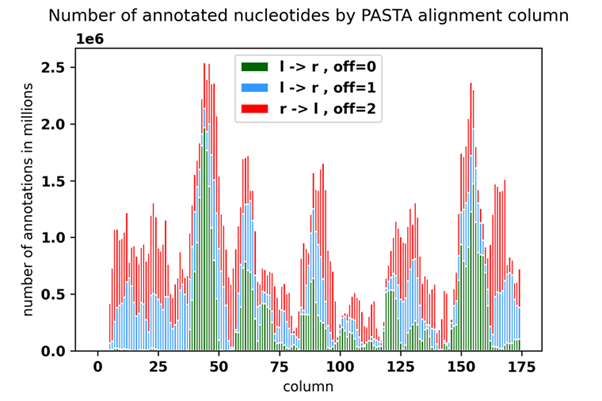
As you can see, we have reached a decent coverage of each column of the alignment, with a variety of different categories. Note that some regions are more represented than others because they seemed to generate more “interesting” puzzles for the players (which pushed us to formulate the hypothesis that the problem of realignment was richer in those regions). Also note that for each categories, we have assembled or are assembling thousands of puzzles of the “upside down” version of the same category to help us account for eventual biases in the player solutions.
We will keep reporting on our progress in future blog posts, so we encourage you to stay tuned!

